Contributors
ml.cab.juno is all of us
Our contributors 2
Thank you for supporting ml.cab.juno.
About
Distributed inference
- Pipeline parallel — contiguous layer blocks across JVM nodes; activations flow serially over gRPC.
- Tensor parallel — full depth on each node with head/FFN slices; coordinator AllReduce on logits.
- Zero sidecar processes: coordinator (juno-master) and workers (juno-node) are shaded JVM jars.
GPU acceleration
- NVIDIA CUDA 12.x / cuBLAS and AMD ROCm 6+ / rocBLAS via Panama FFI (java.lang.foreign).
- Auto-selection at startup: CUDA → ROCm → CPU. Override with -Djuno.gpu.backend=cuda|rocm|auto.
- Device-resident FP16 weights; automatic CPU quantised fallback on VRAM OOM.
LoRA fine-tuning
- In-process training REPL: ./juno lora
- Inference overlay: --lora-play PATH (local, cluster, AWS)
- Native merge to standalone GGUF: ./juno merge (patched tensors stored as F32)
OpenAI-compatible REST
- POST /v1/chat/completions (blocking + SSE)
- GET /v1/models, GET /v1/models/{model}
- Enable with --api-port N on ./juno local or cluster mode
- Juno extensions: x_juno_priority, x_juno_session_id, x_juno_top_k
JVM integration
- Maven BOM: cab.ml:juno-bom:0.1.0
- Facade API: JunoPlayer, LoraTrainer, JunoHttpClient
- See docs/howto.md JVM integration section
Observability
- Custom JFR events across matmul, forward pass, token generation, LoRA training
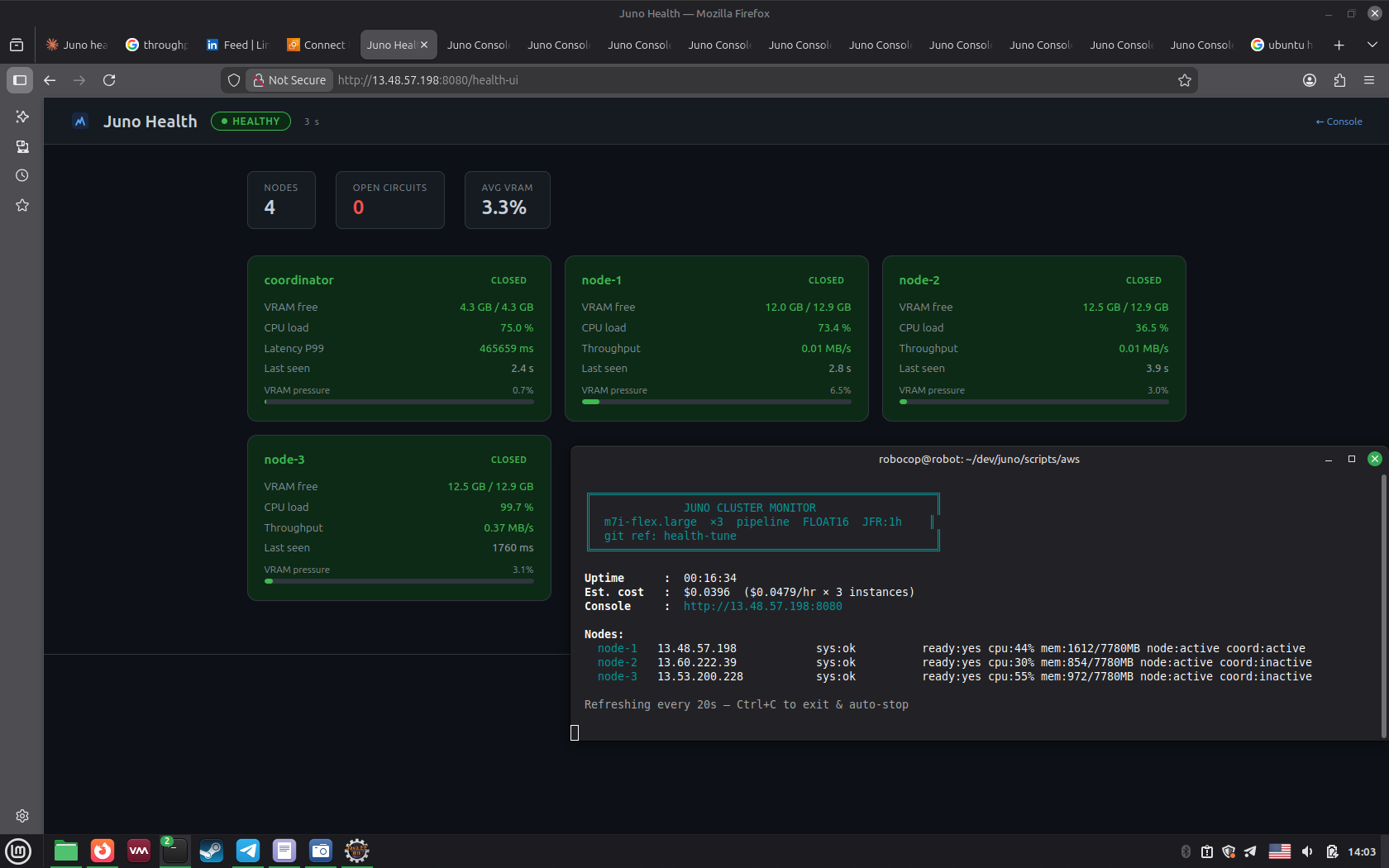
- Health dashboard with per-node CPU load, coordinator P99 latency, node throughput
- Performance matrix: docs/juno_test_matrix.html
Supported models:
GGUF with LLaMA-compatible architectures.
Quantizations: F32, F16, BF16, Q8_0, Q4_0, Q2_K, Q3_K, Q4_K, Q5_K, Q6_K.
Chat templates:
Llama (llama3, mistral, tinyllama/zephyr, chatml) is supported.
Phi (Phi-3 / Phi-3.5) is supported via a dedicated handler and template.
Qwen (gemma, qwen2, qwen3, qwen3moe, qwen3.5) are under development — template and handler groundwork exists for some paths; end-to-end validation is in progress.
Limitations for work in flight: no LoRA on Gemma/Qwen, no thinking-mode template yet, no fused QKV GGUFs on Qwen yet.